

Podstawy Document Object Model
Obiektowy model dokumentu czyli document object model to sposób reprezentacji dokumentów xml i html w postaci modelu zorientowanego
obiektowo. Standard W3C DOM definiuje klasy i interfejsy pozwalające na dostęp do struktury dokumentów oraz jej modyfikację poprzez tworzenie,
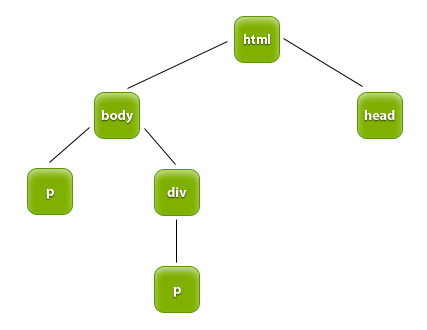
modyfikację i usuwanie węzłów. Dokument jest zbiorem węzłów. Węzły mogą zawierać kolejne podwęzły itd. (spójrz na poniższą ilustrację).
<p id="ident">Witam na mojej stronie</p>W powyższym kodzie węzłem atrybutu jest id="ident".
Pobieranie elementów
DOM posiada metodę getElementById, która pobiera element o określonym identyfikatorze (pamiętaj, że wielkość liter w nazwie metody ma znaczenie). Na przykład
document.getElementById("ident");//odwołanie do obiektu o id="ident"
Metoda getElementsByTagName pozwala znaleźć wszystkie elementy danego typu. Na przykład poniższy kod pozwala pobrać wszystkie elementy p.
document.getElementsByTagName("p");
W celu znalezienia ilości elementów danego typu wystarczy napisać.
document.getElementsByTagName("p").length;
Możemy pobrać również np. wszystkie akapity zawarte w elemencie o określonym id, jak i jego potomkach. Ilustruje to rysunek:
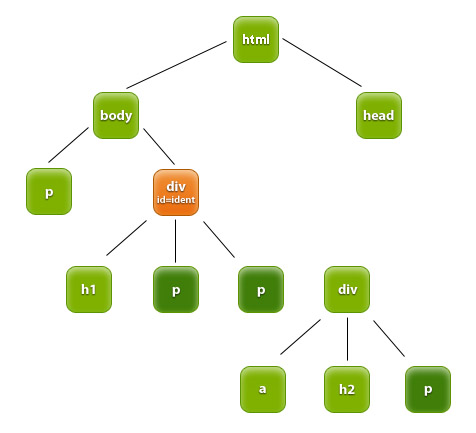
document.getElementById("ident").getElementsByTagName("p");
Do tablicy możemy odwoływać się korzystając z numeru indeksu.
document.getElementsByTagName("p")[0];//zwróci pierwszy akapit
Aby pobrać wszystkie elementy z aktualnej gałęzi (w przypadku document będą to wszystkie elementy dokumentu) należy użyć * - getElementsByTagName("*").
Nowością dodaną w HTML5 DOM jest metoda getElementsByClassName. Służy ona do pobrania elementów o ustalonym atrybucie class.
document.getElementsByClassName("test");//zwróci wszystkie elementy o klasie test
Można również dopasowywać elementy, które mają więcej niż jedną klasę. Nazwy klas oddzielamy wtedy spacją.
document.getElementsByClassName("test przyklad");//zwróci wszystkie elementy, które posiadają zarówno klasę test jak i przyklad
Metoda getElementsByClassName jest obsługiwana tylko przez nowoczesne przeglądarki. Dla starszych przeglądarek musimy napisać własną
wersję tej metody używając innych dostępnych funkcji DOM.
function getElementsByClassName(node, classname) {
if (node.getElementsByClassName) {
// Używamy wbudowanej metody
return node.getElementsByClassName(classname);
} else {
var results = [];
var elems = node.getElementsByTagName("*");
for (var i = 0; i < elems.length; i++) {
if (elems[i].className.indexOf(classname) != -1)
{
results[results.length] = elems[i];
}
}
return results;
}
}
Zabawa z atrybutami
Funkcja getAttribute pobiera wartość wskazanego atrybutu. Jeśli element nie posiada szukanego atrybutu funkcja zwraca null.
var el = document.getElementById("ident");
el.getAttribute("id");//zwróci wartość atrybutu id
Jeśli chcemy zmienić wartość atrybutu musimy użyć funkcji setAttribute. Przyjmuje ona dwa parametry: nazwę atrybutu i jego wartość.
Ważną uwagą jest to, że atrybut dodajemy przed dodaniem elementu do rodzica.
var el = document.getElementById("ident");
el.setAttribute("class","klasa");//dodajemy atrubut class o wartości klasa
W celu usunięcia atrybutu należy użyć metody removeAttribute. Usuwa ona wskazany atrybut.
el.removeAttribute("class");//usuwa atrubut class
Istnieje jeszcze metoda hasAttributes, która sprawdza czy węzeł posiada atrybuty. Zwraca true jeśli tak, a false w przeciwnym razie.
Relacje w DOM
Teraz przedstawię metody i właściwości pomocne przy manipulowaniu drzewem DOM. Właściwość parentNode odwołuje się do rodzica bieżącego węzła.
var el = document.getElementById("test").parentNode;
Właściwość childNodes zwraca tablicę zawierającą dzieci określonego węzła.
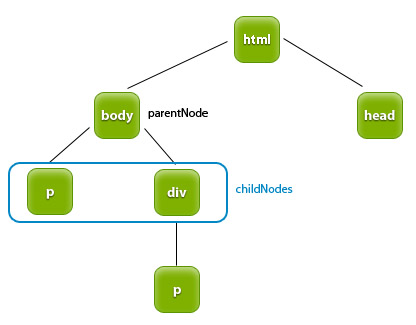 Jak widać na powyższym rysunku drugi element p nie jest dzieckiem, lecz potomkiem elementu body. Nie będzie on więc
uwzględniony w tablicy childNodes dla body. Oczywiście do poszczególnych elementów tablicy możemy się odwoływać.
Jak widać na powyższym rysunku drugi element p nie jest dzieckiem, lecz potomkiem elementu body. Nie będzie on więc
uwzględniony w tablicy childNodes dla body. Oczywiście do poszczególnych elementów tablicy możemy się odwoływać.
var el = document.getElementById("test").childNodes;
el_pierwszy = el[0];
el_drugi = el[1];
Istnieje również metoda hasChildNodes(), która zwraca true jeśli węzeł posiada dzieci, a false w przeciwnym razie.
Ilustracją właściwości firstChild i lastChild jest poniższy rysunek.
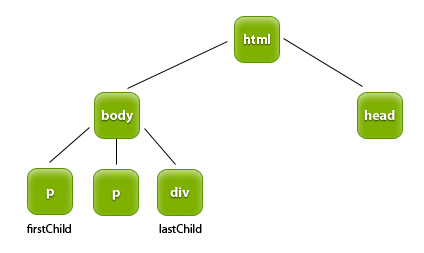 firstChild zwraca pierwszy element potomny węzła. Dla węzłów zawierających tekst (np. p, h1) pierwszym węzłem potomnym jest węzeł tekstowy.
lastChild zwraca ostatni element potomny węzła. node.firstChild jest równoważne node.childNodes[0], a
node.lastChild node.childNodes[node.childNodes.length - 1].
Kolejne właściwości to nextSibling i previousSibling. Dają one możliwość dostępu do węzła równorzędnego po bieżącym (następny brat) i
węzła równorzędnego prze bieżącym (poprzedni brat). Najlepiej zilustruje to poniższy rysunek.
firstChild zwraca pierwszy element potomny węzła. Dla węzłów zawierających tekst (np. p, h1) pierwszym węzłem potomnym jest węzeł tekstowy.
lastChild zwraca ostatni element potomny węzła. node.firstChild jest równoważne node.childNodes[0], a
node.lastChild node.childNodes[node.childNodes.length - 1].
Kolejne właściwości to nextSibling i previousSibling. Dają one możliwość dostępu do węzła równorzędnego po bieżącym (następny brat) i
węzła równorzędnego prze bieżącym (poprzedni brat). Najlepiej zilustruje to poniższy rysunek.
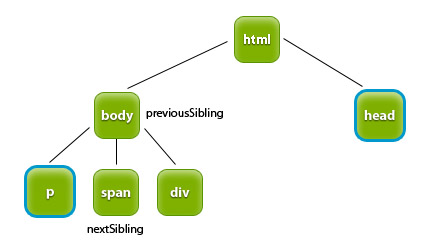 Dla elementu head previousSibling jest body. Natomiast dla p nextSibling
jest element span.
Przyjrzymy się teraz trzem właściwościom: nodeType, nodeName i nodeValue. Dwie pierwsze są tylko do odczytu. nodeType zwraca liczbę całkowitą
określającą typ węzła np. 1 - dla zwykłych znaczników html, 2 - dla węzłów atrybutu, 3 - węzeł tekstowy, 9 - węzeł dokumentu itd. Pełną listę zwracanych liczb i typów można znaleźć
na developer.mozilla.org. nodeName - zwraca nazwę węzła (nie id). Dla węzłów opartych na
znacznikach html nazwą jest po prostu nazwa znacznika np. p lub body. Dla węzła dokumentu nazwą jest specjalny kod #document, analogicznie węzły tekstowe mają nazwę #text. Nazwa
węzła atrybutu jest po prostu nazwą atrybutu. nodeValue zwraca tekst zawarty w węźle tekstowym, dla węzła atrybutu zwracana jest wartość atrybutu.
Spójrzmy na poniższy przykład. Zmienia on tekst elementu z pomocą nodeValue. Zanim to nastąpi sprawdzamy czy dziecko jest węzłem tekstowym.
Dla elementu head previousSibling jest body. Natomiast dla p nextSibling
jest element span.
Przyjrzymy się teraz trzem właściwościom: nodeType, nodeName i nodeValue. Dwie pierwsze są tylko do odczytu. nodeType zwraca liczbę całkowitą
określającą typ węzła np. 1 - dla zwykłych znaczników html, 2 - dla węzłów atrybutu, 3 - węzeł tekstowy, 9 - węzeł dokumentu itd. Pełną listę zwracanych liczb i typów można znaleźć
na developer.mozilla.org. nodeName - zwraca nazwę węzła (nie id). Dla węzłów opartych na
znacznikach html nazwą jest po prostu nazwa znacznika np. p lub body. Dla węzła dokumentu nazwą jest specjalny kod #document, analogicznie węzły tekstowe mają nazwę #text. Nazwa
węzła atrybutu jest po prostu nazwą atrybutu. nodeValue zwraca tekst zawarty w węźle tekstowym, dla węzła atrybutu zwracana jest wartość atrybutu.
Spójrzmy na poniższy przykład. Zmienia on tekst elementu z pomocą nodeValue. Zanim to nastąpi sprawdzamy czy dziecko jest węzłem tekstowym.
var obj = document.getElementById('divone');
if(obj.firstChild.nodeType == 3)
{
obj.firstChild.nodeValue = 'nowy tekst';
}
Tworzenie elementów
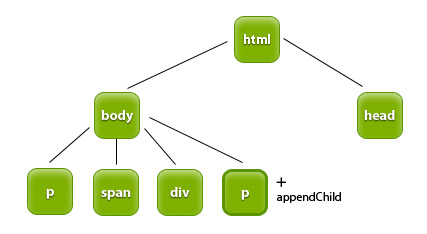
Dodawanie elementu do drzewa DOM odbywa się w dwóch krokach: najpierw tworzymy nowy element metodą createElement, a później dodajemy go do drzewa. Poniżej tworzymy nowy paragraf, ale nie jest on jeszcze dodany do drzewa.
var paragraf = document.createElement('p');
Teraz aby dodać nowo utworzony paragraf do drzewa dokumentu korzystamy z appendChild. appendChild dołącza wskazany nowy węzeł
po wszystkich istniejących węzłach obiektu. Poprzednio utworzyliśmy paragraf teraz dodamy go do dokumentu wewnątrz body.
document.body.appendChild(paragraf);
 Metoda createTextNode służy do tworzenia wezłów tekstowych.
Metoda createTextNode służy do tworzenia wezłów tekstowych.
var tekst = document.createTextNode('przykładowy tekst');
//Teraz dołączymy tekst do jakiegoś znacznika
paragraf.appendChild(tekst);
Jeśli chcemy usunąć węzeł możemy wykorzystać metodę removeChild, która usuwa istniejący węzeł potomny. Na przykład dla następującej struktury w dokumencie.
<div id="blok"> <p id="paragraf"></p> </div>W celu usunięcia paragrafu musimy napisać kod taki jak poniżej.
var d = document.getElementById('blok');
var p = document.getElementById('paragraf');
var usuwany_wezel = d.removeChild(p);
Spójrzmy też na poniższy kod. Z elementu nadrzędnego usuwamy dziecko.
var node = document.getElementById('nadrzedny');
node.removeChild(node.childNodes[0]);
Omówię teraz na przykładzie funkcję replaceChild(węzeł, stary_węzeł), która zastępuje wskazany stary węzeł potomny nowym. Załóżmy, że mamy
poniższą strukturę w dokumencie html.
<div id="parent"> <p>One</p> </div>Zastosujmy teraz kod javascript.
var rodzic = document.getElementById('parent');
nowypar = document.createElement('p');
text = document.createTextNode('Two');
nowypar.appendChild(text);
rodzic.replaceChild(nowypar, rodzic.firstChild);
Po wykonaniu kodu z powyższego listingu będziemy mieli następującą strukturę w dokumencie.
<div id="parent"> <p>Two</p> </div>Kolejna metoda insertBefore(węzeł, stary_węzeł) jak sama nazwa wskazuje wstawia nowy węzeł przed wskazanym istniejącym węzłem potomnym. Tak jak poprzednio najlepiej w zrozumieniu pomoże nam przykład. Mamy następującą strukturę.
<div> <span id="child">Tekst 1</span> </div>Kod javascript przedstawia poniższy listing. Komentarze w kodzie objaśniają każdą linię.
var sp = document.createElement('span'); //tworzymy nowy element span
var text = document.createTextNode('Nowy element span'); //tworzymy nowy węzeł tekstowy
sp.appendChild(text); //dołączamy text do utworzonego wcześniej spana
var child = document.getElementById('child'); // łapiemy element o id child
var parent = child.parentNode; // ... oraz jego rodzica
parent.insertBefore(sp, child); //wstawiamy nowy span przed span o id="child"
W wyniku otrzymujemy:
<div> <span>Nowy element span</span> <span id="child">Tekst 1</span> </div>Nie istnieje metoda insertAfter, jednak można ją emulować poprzez kombinację insertBefore oraz nextSibling. W powyższym przykładzie sp może zostać wstawione za span o id child przy użyciu parent.insertBefore(sp, child.nextSibling). Jeśli child nie posiada następnego rodzeństwa i musi być ostatnim potomnym child.nextSibling zwróci null, więc sp będzie wstawione na końcu listy węzłów potomnych. Ostatnią metodą, którą poznamy jest cloneNode(głębokość). Zwraca ona kopię bieżącego węzła. Głębokość to wartość logiczna oznaczająca czy kopiowanie ma być głębokie czy nie. Spójrzmy na przykład.
var p = document.getElementById('paragraf');
kopia = p.cloneNode(true);
Kopia węzła zwrócona przez cloneNode() nie ma rodzica. Podczas klonowania węzła skopiowane zostają wszystkie jego atrybuty i ich wartości, ale
nie zostaje skopiowana treść zawarta w węźle, ponieważ treść ta przechowywana jest w węźle potomnym typu Text. Głębokie klonowanie kopiuje i zwraca węzeł wraz z całym
drzewem pod nim się znajdującym (w tym treścią z potomnych węzłów typu Text).